import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
public class neo {
//實作Comparator的介面宣告compare方法
private class ValueComparator implements Comparator<Map.Entry<String, Integer>>
{
public int compare(Map.Entry<String, Integer> mp1, Map.Entry<String, Integer> mp2)
{
//大到小mp2-mp1,小到大mp1-mp2
return mp2.getValue() - mp1.getValue();
}
}
public List<String> showsortedlist(Map<String, Integer> map)
{
//先把HashMap轉成List形式
List<Map.Entry<String, Integer>> sortedlist = new ArrayList<Map.Entry<String, Integer>>(map.size());
//把map中所有東西丟到sortedlist
sortedlist.addAll(map.entrySet());
ValueComparator vc = new ValueComparator();
//利用Collections.sort排序sortedlist
Collections.sort(sortedlist, vc);
final List<String> sortedvalue_keys = new ArrayList<String>(map.size());
Iterator iter = sortedlist.iterator();
while (iter.hasNext()) {
Entry<String, Integer> data = (Entry<String, Integer>) iter.next();
Object key = data.getKey();
Object val = data.getValue();
System.out.println(key+"=>"+val);
sortedvalue_keys.add((String) key);
}
return sortedvalue_keys;
}
public static void main(String args[]){
Map<String,Integer> map = new HashMap<String,Integer>();
map.put("20030120" , new Integer (56));
map.put("20030118" , new Integer (19));
map.put("20030125" , new Integer (25));
map.put("20030122" , new Integer (32));
map.put("20030117" , new Integer (67));
map.put("20030123" , new Integer (34));
map.put("20030124" , new Integer (42));
map.put("20030121" , new Integer (19));
map.put("20030119" , new Integer (98));
Iterator iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
Object key = entry.getKey();
Object val = entry.getValue();
System.out.println(key+"=>"+val);
}
System.out.println("開始排序");
neo gosort = new nothing();
gosort.showsortedlist(map);
}
}
2012年4月25日 星期三
JAVA的HashMap對value排序
2012年4月24日 星期二
ubuntu安裝JDK&JRE
手動安裝JDK
sudo apt-get install python-software-properties
sudo add-apt-repository ppa:ferramroberto/java
sudo apt-get update
sudo apt-get install sun-java6-jdk
==================================================
手動安裝JRE
sudo apt-get install python-software-properties
sudo add-apt-repository ppa:ferramroberto/java
sudo apt-get update
sudo apt-get install sun-java6-jre sun-java6-plugin sun-java6-fonts
sudo apt-get install python-software-properties
sudo add-apt-repository ppa:ferramroberto/java
sudo apt-get update
sudo apt-get install sun-java6-jdk
==================================================
手動安裝JRE
sudo apt-get install python-software-properties
sudo add-apt-repository ppa:ferramroberto/java
sudo apt-get update
sudo apt-get install sun-java6-jre sun-java6-plugin sun-java6-fonts
Particle Filter tracking
先假設tracking符合Markov性質

Xk表示在時間k目標的位置Vk表示在時間k的系統誤差

Zk表示在時間k測量到的目標位置nk表示在時間k的測量誤差
根據Chapman-Kolmogorov equation

在Markov性質下

Chapman-Kolmogorov equation可化簡成下式

所以p(xk|z1:k-1)可得如下公式,其中1:k-1表示由時間1到k-1

上式中p(xk-1|z1:k-1)在時間k-1時已經求得且p(xk|xk-1)可由xk=fk(xk-1,vk-1)計算得到
在時間k時,假設已經得到zk


其中p(zk|xk)可由測量公式zk=hk(xk,nk)得到
合併以上式子可得,其中alpha為上式的1/p(zk|z1:k-1)就是正規化因子

Prior Distribution : P(x0) 通常我們會假設為均勻分布
Transition Model : P(xt|xt-1)表示在兩個frame間目標物的移動情形
Observation Model : P(yt,xt) 表示在xt位置點上是否為目標物的likelihood
以下是Rob Hess的程式示例
他對p(xt|xt-1)有兩種,一種是當作常態分布,即當前位置的附近出現機率較高
一種是考慮速度,加速度的估計
Rob Hess考慮了second-order的動態方程式
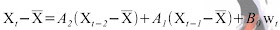
即需考慮前兩個frame的位置,速度,加速度和雜訊來估計Xt
Observation Model p(yt|xt) 的部分他使用hsv histogram-base model


上面D是對原來目標物和現在的xt上的物體hsv相似度
這裡的Particle Filter他是使用sequential Monte Carlo sampling
所以particle會有weight使得particle的分佈接近filter估計的分佈

底下是說明
當上一個frame的p(xt-1|y1:t-1)經過particle filter求出且resample之後
下一個frame
我們利用transition model估計出新的位置(xt|y1:t-1)
經過transition model移動過的新的particle分布可視為是p(xt|xt-1)
因為上一個frame時的weight會使weight高的particle在同一個位置有多個particle所以可視為是

我們利用這新位置的所有particle算出這一個frame的histogram和上一frame的histogram比較相似度p(yt|xt)計算likelihood當作新的weight
把所有的weight乘particle相加起來其實就是指所有particle的分佈情形

新的particle filter分布p(xt|yt)即利用所有這些particle的likelihood

選出最高的weight的particle就是我們的估計位置(xt|y1:t-1)
再利用所有particle的weight可重新resample作出新的particle,依weight高的地方灑出較多的particle
反覆上述動作即為PF
Xk表示在時間k目標的位置Vk表示在時間k的系統誤差
Zk表示在時間k測量到的目標位置nk表示在時間k的測量誤差
根據Chapman-Kolmogorov equation
在Markov性質下
Chapman-Kolmogorov equation可化簡成下式
所以p(xk|z1:k-1)可得如下公式,其中1:k-1表示由時間1到k-1
上式中p(xk-1|z1:k-1)在時間k-1時已經求得且p(xk|xk-1)可由xk=fk(xk-1,vk-1)計算得到
在時間k時,假設已經得到zk
其中p(zk|xk)可由測量公式zk=hk(xk,nk)得到
合併以上式子可得,其中alpha為上式的1/p(zk|z1:k-1)就是正規化因子

Prior Distribution : P(x0) 通常我們會假設為均勻分布
Transition Model : P(xt|xt-1)表示在兩個frame間目標物的移動情形
Observation Model : P(yt,xt) 表示在xt位置點上是否為目標物的likelihood
以下是Rob Hess的程式示例
他對p(xt|xt-1)有兩種,一種是當作常態分布,即當前位置的附近出現機率較高
一種是考慮速度,加速度的估計
Rob Hess考慮了second-order的動態方程式
即需考慮前兩個frame的位置,速度,加速度和雜訊來估計Xt
Observation Model p(yt|xt) 的部分他使用hsv histogram-base model

上面D是對原來目標物和現在的xt上的物體hsv相似度
這裡的Particle Filter他是使用sequential Monte Carlo sampling
所以particle會有weight使得particle的分佈接近filter估計的分佈
底下是說明

當上一個frame的p(xt-1|y1:t-1)經過particle filter求出且resample之後
下一個frame
我們利用transition model估計出新的位置(xt|y1:t-1)
經過transition model移動過的新的particle分布可視為是p(xt|xt-1)
因為上一個frame時的weight會使weight高的particle在同一個位置有多個particle所以可視為是
我們利用這新位置的所有particle算出這一個frame的histogram和上一frame的histogram比較相似度p(yt|xt)計算likelihood當作新的weight
把所有的weight乘particle相加起來其實就是指所有particle的分佈情形

新的particle filter分布p(xt|yt)即利用所有這些particle的likelihood

選出最高的weight的particle就是我們的估計位置(xt|y1:t-1)
再利用所有particle的weight可重新resample作出新的particle,依weight高的地方灑出較多的particle
反覆上述動作即為PF
2012年4月23日 星期一
differential convolution
一階導數(First-order derivative)

二階導數(Second-order derivative)

在影像上The Laplacian

所以可得到



用matlab呈現
二階導數(Second-order derivative)

在影像上The Laplacian

所以可得到

故影像銳化convolutionj二階微分算子可以有如下形式

在影像上一階導數可用sobel,下圖左為X方向梯度,右為Y方向梯度中間取2可以抑制雜訊
還有高斯形式,下突即為Y方向梯度的高斯形式

用matlab呈現
sigma = 1.5; [x,y]=ndgrid(floor(-3*sigma):ceil(3*sigma),floor(-3*sigma):ceil(3*sigma)); %若sigma=2 %x=|-2 -2 -2 -2| % |-1 -1 -1 -1| % | 0 0 0 0| % | 1 1 1 1| % | 2 2 2 2| DGaussx=-(x./(2*pi*sigma^4)).*exp(-(x.^2+y.^2)/(2*sigma^2)); DGaussy=-(y./(2*pi*sigma^4)).*exp(-(x.^2+y.^2)/(2*sigma^2)); Ix = imfilter(I,DGaussx,'conv'); %x方向梯度 Iy = imfilter(I,DGaussy,'conv'); %y方向梯度
Lucas-Kanade Optical Flow

令I(x,y,t)表示在t時間時座標(x,y)的圖像值,假設dt時間內該目標移動了(dx,dy)
讓右邊經過一階泰勒展開

消去I(x,y,t)可得以下等式
同除dt並令u=(dx/dt),v=(dy/dt),(u,v)即為像素值在該時間的速度,稱之為光流
上式可改寫為

假設只討論小區域內的(u,v)光流分析

改寫上式為

目標是解 min(|Au-b|^2),所以可以得到u矩陣即為所求

clear;
im1=single((rgb2gray(imread('data\46.jpg'))));
im2=single((rgb2gray(imread('data\47.jpg'))));
numLevels=3; %作幾層金字塔
window=9; %小區域計算光流的區域呎吋
iterations=1;
alpha = 0.001;
hw = floor(window/2);
t0=clock;
pyramid1 = im1;
pyramid2 = im2;
for i=2:numLevels %1最大3最小
im1 = impyramid(im1, 'reduce');
im2 = impyramid(im2, 'reduce');
pyramid1(1:size(im1,1), 1:size(im1,2), i) = im1;
pyramid2(1:size(im2,1), 1:size(im2,2), i) = im2;
end;
for p = 1:3
im1 = pyramid1(1:(size(pyramid1,1)/(2^(numLevels - p))), 1:(size(pyramid1,2)/(2^(numLevels - p))), (numLevels - p)+1);
im2 = pyramid2(1:(size(pyramid2,1)/(2^(numLevels - p))), 1:(size(pyramid2,2)/(2^(numLevels - p))), (numLevels - p)+1);
if p==1
u=zeros(size(im1));
v=zeros(size(im1));
else
%resizing
u = 2 * imresize(u,size(u)*2,'bilinear');
v = 2 * imresize(v,size(v)*2,'bilinear');
end
for r = 1:iterations
u=round(u);
v=round(v);
for i = 1+hw:size(im1,1)-hw
for j = 1+hw:size(im2,2)-hw
%作小區域的圖像patch1,patch2
patch1 = im1(i-hw:i+hw, j-hw:j+hw);
%moved patch
lr = i-hw+v(i,j);
hr = i+hw+v(i,j);
lc = j-hw+u(i,j);
hc = j+hw+u(i,j);
if (lr < 1)||(hr > size(im1,1))||(lc < 1)||(hc > size(im1,2))
%Regularized least square processing
else
patch2 = im2(lr:hr, lc:hc);
fx = conv2(patch1, 0.25* [-1 1; -1 1]) + conv2(patch2, 0.25*[-1 1; -1 1]);
fy = conv2(patch1, 0.25* [-1 -1; 1 1]) + conv2(patch2, 0.25*[-1 -1; 1 1]);
ft = conv2(patch1, 0.25*ones(2)) + conv2(patch2, -0.25*ones(2));
Fx = fx(2:window-1,2:window-1)';
Fy = fy(2:window-1,2:window-1)';
Ft = ft(2:window-1,2:window-1)';
A = [Fx(:) Fy(:)];
G=A'*A;
G(1,1)=G(1,1)+alpha; G(2,2)=G(2,2)+alpha;
%U = G反矩陣*A'*(-Ft)
U=1/(G(1,1)*G(2,2)-G(1,2)*G(2,1))*[G(2,2) -G(1,2);-G(2,1) G(1,1)]*A'*-Ft(:);
u(i,j)=u(i,j)+U(1); v(i,j)=v(i,j)+U(2);
end
end
end
end
end
x=135;
y=170;
figure(1)
im1=((rgb2gray(imread('data\46.jpg'))));
imshow(im1);
hold on
plot(x,y,'r');
figure(2)
im1=((rgb2gray(imread('data\47.jpg'))));
imshow(im1);
hold on
plot(x+u(x,y),y+v(x,y),'g');
u(x,y)
v(x,y)
2012年4月22日 星期日
Genetic Algorithm solve Optimization Problem
遺傳演算法的三個主要運算子為複製(reproduction)或稱選擇、交配(crossover)、以及突變 (mutation)。

遺傳演算法來解最佳化問題的基本歩驟:
1)將問題要處理的所有資料編碼成稱為染色體(chromosonl)的字串
2)依問題的複雜程度,由所有染色體中隨機産生n個初始字串,這n個染色體可被稱為母體、族群(Population)
3)定義選擇規則(Selection),依據求解之條件設計的適應函數(fitness function)來選出)適應值高的染色體到交配池(mating pool)中,挑選過程中依適應值高低比例複製(reproduction)到交配池中
4)再依交配(crossover)及突變 (mutation)過程的運算繁衍出子孫(offspring),到此為一個世代(Generation)
5)在毎一個世代中,都要對所新産生的染色體,評估其適應性(Fitness)評估否正在逼近問題的最佳解。
6)利用選擇規則(Selection),將具有高適應性的子代保留,以形成新的母代族群進行下一輪的遺傳過程。
經過幾個世代之後,最後演算法會收歛至最佳的染色體。

Selection (選擇)方法之一:
輪盤法(Roulette Wheel )


原則上 適應性愈高之染色體被複製的機率愈大;因以機率隨機選擇,故適合度低的染色體仍有機會被複製。
crossover(交配)方法之一:
Single point crossover (單點交配)

在選擇的兩條染色體中,隨機選取一個交配點,並交換兩條染色體中此交配點後所有位元。
Mutation (突變)方法之一:
二元編碼之突變:
隨機選擇1或多個bits做數値反轉的動作。

若突變率為0.1,上述染色體(chromosonl)長度為8,母體(Population)假設有5條,那麼就有40個bits,突變率0.1表示有4個bits要突變,若為隨機選擇1個bit就是5條挑4條隨機選擇位置反轉1個bit
設定停止條件:
1)執行設定的世代數
2)前後世代最佳值之差異低於設定的極小值
3)成熟率大於設定值
成熟率表示族群中有多少比例的染色體具有相同的基因,當族群中絕大部分的染色體都具有相同基因時,交配也無法産生一個不同的子代,此時即為收斂(亦稱為成熟)。例如設定成熟率 ≥80%時停止
範例
欲求解f(x)的最大值,其中f(x) = x^2,x 為介於 0至31間的整數。
在運用遺傳演算法求解最佳化問題時,需事先規劃三個主要問題:
決定編碼型態 ((Encoding) Encoding)
決定遺傳演算法的演化機制(Select Crossover Mutation)
定義適應函數(Fitness Function)
編碼 (Encoding) 型態方式上,利用二進位的位元編碼方式,將十進位數值0編成00000的位元,十進位數值31 編成 11111 的位元。
選擇 (Select) 的方法上我們使用輪盤選擇法(roulette wheel selection)
交配的機制我們選擇單點交配(single point crossover),並將交配機率設定為 1.0
突變的機制選擇單點突變(one point mutation),並將突變機率設定為 0.1
適應函數 (Fitness Function):我們可以直接以此函數當做為適應函數,即:f(x) = x^2 .
Step 1:
我們設定族群大小為 4,由問題之解答空間隨機抽取四個數値:
-------------------------------------------------
母代編號 隨機抽取之數値 x 二元編碼
1 14 01110
2 24 11000
3 17 10001
4 7 00111
-------------------------------------------------
Step2:
計算現有族群中毎一條染色體的適合度値(Fitness value)。
-----------
x f(x)
14 196
24 576
17 289
7 49
----------
Step3:
選擇:自現有族群中,以輪盤法依毎條染色體的適合度比例,重複隨機選擇染色體

在起始族群中的第一個字串被複製一個至交配池中,第二個字串被複製二個至交配池中,第三個字串被複製一個至交配池中,第四個字串則被淘汰。由上表得知,計算出來的期望值 (第四欄) 與真實的複製個數很接近。亦即適應度高的字串被大量複製到下一子代;而適應度低的字串則被淘汰。
Step4:
交配:隨機至交配池中抽取兩母代,以隨機産生的交配點進行交配産生子代,並計算子代的適合度

Step5:
突變:由於我們設定的突變機率為 0.1,而族群中的基因總數為族群大小乘上毎個字串的編碼位元數,也就是 4 ×5 = 20。因此,族群中將被突變的基因總數為 20 ×0.1 = 2,亦即,有兩個基因將被突變。我們隨機地挑選兩個字串中的各一個基因來作突變,並計算突變後的適度。
Step6:測試停止條件
測試是否符合停止條件。若是則停止,否則回至歩驟3,以進行下一代的演化。
遺傳演算法則之主要特性
遺傳演算法則是以"參數編碼"的方式進行運算而不是參數本身,因此可以跳脱搜尋空間上的限制。
遺傳演算法則同時考慮搜尋空間上多個點 多個點而不是單一個點,因此可以比傳統的啓發式解法較快地獲得整體最佳解 整體最佳解(global optimum), 並 可 以 降 低 陷 入 區 域 最 佳 值(local optimum)的機會,此項特性是遺傳演算法則的最大優點。
遺傳演算法只使用適應函數 適應函數作為判斷依據,而不需要其它輔助的資訊(例如梯度),因此可以使用各種型態的適應函數,並可免除許多繁雜的計算與推導。
遺傳演算法使用機率規則 機率規則方式去引導搜尋方向,屬於盲目的搜尋方法,而不是採用明確的規則,因此較能符合各種不同類型的最佳化問題。
問題
基因表達是以離散的方式加以呈現,故較難應用於求解連續變數之問題。較適用於求解整數變數,離散變數,二元變數等。
係將決策變數編碼為基因方式組成染色體求解,若問題決策變數甚多,導致染色體長度過長,超過電腦記憶體量限制,且結果不佳
仍無法保証求得最佳解
無記憶性,因此會重複搜尋相同的點,增加運作成本
遺傳演算法來解最佳化問題的基本歩驟:
1)將問題要處理的所有資料編碼成稱為染色體(chromosonl)的字串
2)依問題的複雜程度,由所有染色體中隨機産生n個初始字串,這n個染色體可被稱為母體、族群(Population)
3)定義選擇規則(Selection),依據求解之條件設計的適應函數(fitness function)來選出)適應值高的染色體到交配池(mating pool)中,挑選過程中依適應值高低比例複製(reproduction)到交配池中
4)再依交配(crossover)及突變 (mutation)過程的運算繁衍出子孫(offspring),到此為一個世代(Generation)
5)在毎一個世代中,都要對所新産生的染色體,評估其適應性(Fitness)評估否正在逼近問題的最佳解。
6)利用選擇規則(Selection),將具有高適應性的子代保留,以形成新的母代族群進行下一輪的遺傳過程。
經過幾個世代之後,最後演算法會收歛至最佳的染色體。
Selection (選擇)方法之一:
輪盤法(Roulette Wheel )


原則上 適應性愈高之染色體被複製的機率愈大;因以機率隨機選擇,故適合度低的染色體仍有機會被複製。
crossover(交配)方法之一:
Single point crossover (單點交配)

在選擇的兩條染色體中,隨機選取一個交配點,並交換兩條染色體中此交配點後所有位元。
Mutation (突變)方法之一:
二元編碼之突變:
隨機選擇1或多個bits做數値反轉的動作。
若突變率為0.1,上述染色體(chromosonl)長度為8,母體(Population)假設有5條,那麼就有40個bits,突變率0.1表示有4個bits要突變,若為隨機選擇1個bit就是5條挑4條隨機選擇位置反轉1個bit
設定停止條件:
1)執行設定的世代數
2)前後世代最佳值之差異低於設定的極小值
3)成熟率大於設定值
成熟率表示族群中有多少比例的染色體具有相同的基因,當族群中絕大部分的染色體都具有相同基因時,交配也無法産生一個不同的子代,此時即為收斂(亦稱為成熟)。例如設定成熟率 ≥80%時停止
範例
欲求解f(x)的最大值,其中f(x) = x^2,x 為介於 0至31間的整數。
在運用遺傳演算法求解最佳化問題時,需事先規劃三個主要問題:
決定編碼型態 ((Encoding) Encoding)
決定遺傳演算法的演化機制(Select Crossover Mutation)
定義適應函數(Fitness Function)
編碼 (Encoding) 型態方式上,利用二進位的位元編碼方式,將十進位數值0編成00000的位元,十進位數值31 編成 11111 的位元。
選擇 (Select) 的方法上我們使用輪盤選擇法(roulette wheel selection)
交配的機制我們選擇單點交配(single point crossover),並將交配機率設定為 1.0
突變的機制選擇單點突變(one point mutation),並將突變機率設定為 0.1
適應函數 (Fitness Function):我們可以直接以此函數當做為適應函數,即:f(x) = x^2 .
Step 1:
我們設定族群大小為 4,由問題之解答空間隨機抽取四個數値:
-------------------------------------------------
母代編號 隨機抽取之數値 x 二元編碼
1 14 01110
2 24 11000
3 17 10001
4 7 00111
-------------------------------------------------
Step2:
計算現有族群中毎一條染色體的適合度値(Fitness value)。
-----------
x f(x)
14 196
24 576
17 289
7 49
----------
Step3:
選擇:自現有族群中,以輪盤法依毎條染色體的適合度比例,重複隨機選擇染色體
在起始族群中的第一個字串被複製一個至交配池中,第二個字串被複製二個至交配池中,第三個字串被複製一個至交配池中,第四個字串則被淘汰。由上表得知,計算出來的期望值 (第四欄) 與真實的複製個數很接近。亦即適應度高的字串被大量複製到下一子代;而適應度低的字串則被淘汰。
Step4:
交配:隨機至交配池中抽取兩母代,以隨機産生的交配點進行交配産生子代,並計算子代的適合度
Step5:
突變:由於我們設定的突變機率為 0.1,而族群中的基因總數為族群大小乘上毎個字串的編碼位元數,也就是 4 ×5 = 20。因此,族群中將被突變的基因總數為 20 ×0.1 = 2,亦即,有兩個基因將被突變。我們隨機地挑選兩個字串中的各一個基因來作突變,並計算突變後的適度。
Step6:測試停止條件
測試是否符合停止條件。若是則停止,否則回至歩驟3,以進行下一代的演化。
遺傳演算法則之主要特性
遺傳演算法則是以"參數編碼"的方式進行運算而不是參數本身,因此可以跳脱搜尋空間上的限制。
遺傳演算法則同時考慮搜尋空間上多個點 多個點而不是單一個點,因此可以比傳統的啓發式解法較快地獲得整體最佳解 整體最佳解(global optimum), 並 可 以 降 低 陷 入 區 域 最 佳 值(local optimum)的機會,此項特性是遺傳演算法則的最大優點。
遺傳演算法只使用適應函數 適應函數作為判斷依據,而不需要其它輔助的資訊(例如梯度),因此可以使用各種型態的適應函數,並可免除許多繁雜的計算與推導。
遺傳演算法使用機率規則 機率規則方式去引導搜尋方向,屬於盲目的搜尋方法,而不是採用明確的規則,因此較能符合各種不同類型的最佳化問題。
問題
基因表達是以離散的方式加以呈現,故較難應用於求解連續變數之問題。較適用於求解整數變數,離散變數,二元變數等。
係將決策變數編碼為基因方式組成染色體求解,若問題決策變數甚多,導致染色體長度過長,超過電腦記憶體量限制,且結果不佳
仍無法保証求得最佳解
無記憶性,因此會重複搜尋相同的點,增加運作成本
HNN(Hopfield Neural Network)

霍普菲爾網路(HNN)是一種聯想式學習網路從訓練範例中,學習範例的內在記憶規則,以應用於當有不完整輸入狀態資料時,需推論其完整資料,適用於資料擷取與雜訊過濾之應用。

聯想式學習分成兩類:
自聯想 (Auto-associative):由一個樣式聯想同一個樣式者。
異聯想 (Hetero-associative):由一個樣式聯想另一個樣式者。
霍普菲爾網路屬於「自聯想」模式。
先提供許多訓練範例,每個範例有一組二極值{-1, +1}的輸入特徵向量,由這些範例學習一個聯想記憶規則,使網路能記憶這些訓練範例的特徵向量。接著,若有不完整或是有雜訊的資料輸入,網路即能聯想起與其最相近的訓練範例資料。
離散式霍普菲爾網路(輸入只有-1,1)架構如下
學習過程:
假設任意兩處理單元間皆有連結存在。每個處理單元之間的連結加權值,代表兩者間的互動關係。公式如下:
Wij= Σp Xip × Xjp
其中 Wii= 0;p 表示第p 個訓練範例; Xip 表示第 p 個訓練範例中,第 i 個輸入變數值。
所以上述公式為Wij= 所有訓練範例的(第 i 個輸入變數值 *第 i 個輸入變數值)其值相加總和
從公式可得知,如果單元間的加權值為正,代表兩個單元間傾向同號 (同為負或同為正);反之,若加權值為負,代表兩個單元間傾向異號,即:一正一負。
回想過程:
設定網路參數。
讀入加權值矩陣。
輸入一組測試範例的狀態向量X。
開始計算新的狀態向量X。
先算出所有處理單元的加權乘積和:net j= Σi Wij × X
利用 net j
判斷所有處理單元的狀態值是否要更新,方式如下:
若 net j > 0,則處理單元 Xj = 1。
若 net j =0,則處理單元 Xj維持原值。
若 net j <0,則處理單元 Xj = -1。
重覆直到收歛 (狀態向量不再有明顯變化) 或執行一定數目的循環。
利用2×3的黑白點所產生的4組圖樣來做範例

在此,以 -1 代表白點,+1 代表黑點,0 表示未知。以由左到右且由上到下的方式做編碼。四個圖樣所產生的二極值如下所示:

W13= Σp X1p × X3p =(+1)(+1) + (-1)(-1) + (+1)(+1) + (-1)(-1) = 4

回想過程:
讀入一個具有雜訊或不完全的圖樣X

X = {+1, +1, +1, -1, +1, -1}
第一次迭帶:先計算每個處理單元的加權乘積和:

判斷所有處理單元的狀態值是否要更新,
若 net j > 0,則處理單元 Xj = 1。
若 net j =0,則處理單元 Xj維持原值。
若 net j <0,則處理單元 Xj = -1。
故X = {+1, -1, +1, -1, +1, -1}
(第二次迭帶):

因已無狀態變數值改變,因此停止迭帶。結果圖樣為

ART(Adaptive Resonance Theory Network)
自適應共振理論網路(ART)是一種無監督式學習網路,源自於認知學當中的記憶系統,一個好的記憶系統必須具有兩個要求:
穩定性:當新的事物輸入時,舊的事物應適當地保留
可塑性:當新的事物輸入時,應迅速地學習
由於穩定性和可塑性有時會有衝突,因此自適應共振理論網路採用「警戒值測試」(Vigilance Test)來解決此一矛盾。警戒值測試利用一個警戒參數ρ(Vigilance Parameter; 0 < ρ< 1)來做測試,其基本原理如下:
如果新的事物之特性與「某一個」舊的事物之特性夠相似 (即通過警戒值測試),則只修改系統中該舊事物的部份記憶,使其能同時滿足新舊事物之特性,使得舊的事物可適當地保留,如此
可滿足穩定性的要求。
如果新的事物之特性與「所有」舊的事物之特性均不夠相似(即未能通過警戒值測試),則系統為此新事物建立全新的記憶,以迅速地學習此新事物,如此可滿足可塑性的要求。
 一開始輸出層在學習過程初期只有一個,隨著學習的進展會逐漸增加,最後會穩定在一定的數目,學習過程即結束。這和其它神經網路模式輸出層處理單元的數目為固定值很不相同。
一開始輸出層在學習過程初期只有一個,隨著學習的進展會逐漸增加,最後會穩定在一定的數目,學習過程即結束。這和其它神經網路模式輸出層處理單元的數目為固定值很不相同。
每個輸入層處理單元與輸出層處理單元間有兩個連結:由下而上加權值Wb與由上而下加權值W t ,這一點也和其它模式很不相同。
由下而上加權值Wb:
為介於0到1之間,用來計算匹配值。匹配值高的輸出層單元,將優先被用來做警戒值測試。
匹配值計算公式:net j = Σi Wijb × Xi
由上而下加權值Wt:
為0與1之二元值,用來計算相似值。相似值用來與警戒參數做比較,以判斷是否通過警戒值測試。
相似值計算公式:Vj = (Σi Wijt× Xi) /Σ i Xi
學習過程:
1)設定網路參數
Nout = 1 (一開始,輸出部份只有一個類別)
Nin = n (視每一組訓練範例的輸入變數之個數而定)
設定加權矩陣W的初始值
Wi1t = 1
Wi1b = 1/(1+Nin)
2)輸入一組訓練範例 X
3)計算每一個輸出層處理單元與所有輸入層處理單元間的匹配值net j
net j = Σi Wijb × Xi
找出匹配值最大的輸出層處理單元 net j *
net j* = max j(net j)
計算輸出層處理單元 net j* 的相似值
Vj* = (Σi Wij*t × Xi) /Σi Xi
4)測試警戒值 (由匹配值最大的輸出層節點開始)
若 Vj* > ρ
表示輸入資料的特徵與該輸出層節點所表示的特徵夠相似,只需修正該輸出層節點與所有輸入層節點的加權值即可)
若 Vj* < ρ
表示輸入資料的特徵與該輸出層節點所表示的特徵不夠相似,測試下一個輸出神經元直到沒有任一輸出神經元符合此要求就產生新的輸出神經元 (即新的類別)
5_1)修正該輸出層節點與所有輸入層節點的加權值(Wij*表示夠相似的該輸出神經元權值)
Wij*t = Wij*t × Xi
Wij*b = (Wij*t × Xi) / (0.5 + Σi(Wij*t × Xi ))
設定輸出層處理單元的輸出值,令Y j* = 1,而將其餘輸出層處理單元的輸出值設成 0
回到步驟 2
5_2)產生新的輸出神經元
設定Nout = Nout +1
設定新單元與所有輸入層處理單元間之加權值(若Nout=2)
Wi2t = Xi
Wi2b = Xi / (0.5 + Σi(Xi))
令新增的輸出層處理單元Yout= 1,而將其餘輸出層處理單元的輸出值設成 0。
回到步驟 2
6)若完成一個學習循環時沒有新增的類別(即5_2沒執行)則結束訓練
回想過程:
讀入網路參數。
讀入加權值矩陣。
輸入一個測試範例的輸入向量X。
計算匹配值。
找出具有最大匹配值之輸出神經元 j*。
此 j* 即為所求
利用2×3的黑白點所產生的12組圖樣來做範例

在此,以 0 代表白點,以 1 代表黑點,以由左到右且由上到下的方式做編碼。以編號 1的圖樣來說,會產生出一個二元值輸入向量 {1, 0, 1, 0, 1, 0}。
步驟如下:
警戒參數ρ取0.5,Nin = 6,Nout = 1。
Wi1t = 1; Wt = {1, 1, 1, 1, 1, 1}
Wi1b = 1/(1+Nin); Wb = {1/7, 1/7, 1/7, 1/7, 1/7, 1/7} = 1/7 {1, 1, 1, 1, 1, 1}
載入第一個訓練範例 {1, 0, 1, 0, 1, 0}。
匹配值 net1=3/7 = 0.429。
相似值V1= 3/3 = 1,由於相似值大於警戒值,故通過警戒值測試,此輸出層處理單元與所有輸入層處理單元間的加權值
Wt _1 = {1, 0, 1, 0, 1, 0};
Wb _1= 1/(0.5+3){1, 0, 1, 0, 1, 0}
載入第二個訓練範例 {0, 1, 0, 1, 0, 1}。
匹配值 net1= 0/3.5 = 0。
相似值V1= 0/3 = 0,由於相似值不大於警戒值,且無其它輸出層處理單元可作警戒值測試,因此產生第二個輸出層處理單元 (即產生一個新的類別)
W t _2 = {0, 1, 0, 1, 0, 1};
W b _2 = 1/(0.5+3) {0, 1, 0, 1, 0, 1}
載入第三個訓練範例 {1, 1, 1, 0, 0, 0}。
匹配值 net1 = 2/3.5 = 0.571,
第二個單元的匹配值 net2 = 1/3.5 = 0.286
先看V1再看V2
相似值V1= 2/3 = 0.667,由於相似值大於警戒值,故通過警戒值測試,修改此輸出層處理單元與所有輸入層處理單元間的加權值
Wt _1 = {1, 0, 1, 0, 0, 0};
Wb _1 = 1/(0.5+2) {1, 0, 1, 0, 0, 0}
重複上述作數個學習循環,直到在某一個學習循環中,無新的輸出層處理單元產生為止,才停止學習過程。
穩定性:當新的事物輸入時,舊的事物應適當地保留
可塑性:當新的事物輸入時,應迅速地學習
由於穩定性和可塑性有時會有衝突,因此自適應共振理論網路採用「警戒值測試」(Vigilance Test)來解決此一矛盾。警戒值測試利用一個警戒參數ρ(Vigilance Parameter; 0 < ρ< 1)來做測試,其基本原理如下:
如果新的事物之特性與「某一個」舊的事物之特性夠相似 (即通過警戒值測試),則只修改系統中該舊事物的部份記憶,使其能同時滿足新舊事物之特性,使得舊的事物可適當地保留,如此
可滿足穩定性的要求。
如果新的事物之特性與「所有」舊的事物之特性均不夠相似(即未能通過警戒值測試),則系統為此新事物建立全新的記憶,以迅速地學習此新事物,如此可滿足可塑性的要求。

每個輸入層處理單元與輸出層處理單元間有兩個連結:由下而上加權值Wb與由上而下加權值W t ,這一點也和其它模式很不相同。
由下而上加權值Wb:
為介於0到1之間,用來計算匹配值。匹配值高的輸出層單元,將優先被用來做警戒值測試。
匹配值計算公式:net j = Σi Wijb × Xi
由上而下加權值Wt:
為0與1之二元值,用來計算相似值。相似值用來與警戒參數做比較,以判斷是否通過警戒值測試。
相似值計算公式:Vj = (Σi Wijt× Xi) /Σ i Xi
學習過程:
1)設定網路參數
Nout = 1 (一開始,輸出部份只有一個類別)
Nin = n (視每一組訓練範例的輸入變數之個數而定)
設定加權矩陣W的初始值
Wi1t = 1
Wi1b = 1/(1+Nin)
2)輸入一組訓練範例 X
3)計算每一個輸出層處理單元與所有輸入層處理單元間的匹配值net j
net j = Σi Wijb × Xi
找出匹配值最大的輸出層處理單元 net j *
net j* = max j(net j)
計算輸出層處理單元 net j* 的相似值
Vj* = (Σi Wij*t × Xi) /Σi Xi
4)測試警戒值 (由匹配值最大的輸出層節點開始)
若 Vj* > ρ
表示輸入資料的特徵與該輸出層節點所表示的特徵夠相似,只需修正該輸出層節點與所有輸入層節點的加權值即可)
若 Vj* < ρ
表示輸入資料的特徵與該輸出層節點所表示的特徵不夠相似,測試下一個輸出神經元直到沒有任一輸出神經元符合此要求就產生新的輸出神經元 (即新的類別)
5_1)修正該輸出層節點與所有輸入層節點的加權值(Wij*表示夠相似的該輸出神經元權值)
Wij*t = Wij*t × Xi
Wij*b = (Wij*t × Xi) / (0.5 + Σi(Wij*t × Xi ))
設定輸出層處理單元的輸出值,令Y j* = 1,而將其餘輸出層處理單元的輸出值設成 0
回到步驟 2
5_2)產生新的輸出神經元
設定Nout = Nout +1
設定新單元與所有輸入層處理單元間之加權值(若Nout=2)
Wi2t = Xi
Wi2b = Xi / (0.5 + Σi(Xi))
令新增的輸出層處理單元Yout= 1,而將其餘輸出層處理單元的輸出值設成 0。
回到步驟 2
6)若完成一個學習循環時沒有新增的類別(即5_2沒執行)則結束訓練
回想過程:
讀入網路參數。
讀入加權值矩陣。
輸入一個測試範例的輸入向量X。
計算匹配值。
找出具有最大匹配值之輸出神經元 j*。
此 j* 即為所求
利用2×3的黑白點所產生的12組圖樣來做範例

在此,以 0 代表白點,以 1 代表黑點,以由左到右且由上到下的方式做編碼。以編號 1的圖樣來說,會產生出一個二元值輸入向量 {1, 0, 1, 0, 1, 0}。
步驟如下:
警戒參數ρ取0.5,Nin = 6,Nout = 1。
Wi1t = 1; Wt = {1, 1, 1, 1, 1, 1}
Wi1b = 1/(1+Nin); Wb = {1/7, 1/7, 1/7, 1/7, 1/7, 1/7} = 1/7 {1, 1, 1, 1, 1, 1}
載入第一個訓練範例 {1, 0, 1, 0, 1, 0}。
匹配值 net1=3/7 = 0.429。
相似值V1= 3/3 = 1,由於相似值大於警戒值,故通過警戒值測試,此輸出層處理單元與所有輸入層處理單元間的加權值
Wt _1 = {1, 0, 1, 0, 1, 0};
Wb _1= 1/(0.5+3){1, 0, 1, 0, 1, 0}
載入第二個訓練範例 {0, 1, 0, 1, 0, 1}。
匹配值 net1= 0/3.5 = 0。
相似值V1= 0/3 = 0,由於相似值不大於警戒值,且無其它輸出層處理單元可作警戒值測試,因此產生第二個輸出層處理單元 (即產生一個新的類別)
W t _2 = {0, 1, 0, 1, 0, 1};
W b _2 = 1/(0.5+3) {0, 1, 0, 1, 0, 1}
載入第三個訓練範例 {1, 1, 1, 0, 0, 0}。
匹配值 net1 = 2/3.5 = 0.571,
第二個單元的匹配值 net2 = 1/3.5 = 0.286
先看V1再看V2
相似值V1= 2/3 = 0.667,由於相似值大於警戒值,故通過警戒值測試,修改此輸出層處理單元與所有輸入層處理單元間的加權值
Wt _1 = {1, 0, 1, 0, 0, 0};
Wb _1 = 1/(0.5+2) {1, 0, 1, 0, 0, 0}
重複上述作數個學習循環,直到在某一個學習循環中,無新的輸出層處理單元產生為止,才停止學習過程。